
Being able to infer 3D structures from 2D images with geometric principles, vanishing points have been a wellrecognized concept in 3D vision research. It has been widely used in autonomous driving, SLAM, and AR/VR for applications including road direction estimation, camera calibration, and camera pose estimation. Existing vanishing point detection methods often need to trade off between robustness, precision, and inference speed. In this paper, we introduce VaPiD, a novel neural network-based rapid Vanishing Point Detector that achieves unprecedented efficiency with learned vanishing point optimizers. The core of our method contains two components: a vanishing point proposal network that gives a set of vanishing point proposals as coarse estimations; and a neural vanishing point optimizer that iteratively optimizes the positions of the vanishing point proposals to achieve high-precision levels. Extensive experiments on both synthetic and real-world datasets show that our method provides competitive, if not better, performance as compared to the previous state-of-the-art vanishing point detection approaches, while being significantly faster.
Vanishing points are defined as the intersection points of
3D parallel lines when projected onto a 2D image. By providing
geometry-based cues to infer the 3D structures, they
underpin a variety of applications, such as camera calibration
[21, 7], facade detection [25], 3D reconstruction [15],
3D scene structure analysis [16, 39], 3D lifting of lines [30],
SLAM [43], and autonomous driving [22].
Efforts have been made on vanishing point detection in
the past decades. Traditionally, vanishing points are detected
in two stages. In the first stage, a line detection
algorithm, such as probabilistic hough transformation [18]
or LSD [38], is used to extract a set of line segments. In
the second stage, a line clustering algorithm [26] or a voting
procedure [3] is used to estimate the final positions of
vanishing points from detected line segments. The main
weakness of this pipeline is that the extracted lines might be
noisy, leading to spurious results after clustering or voting
when there are too many outliers. To make algorithms more
robust, priors of the underlying scenes can be used, such
as Manhattan worlds [4] or Atlanta worlds [31], which are
common in man-made environments. Nevertheless, additional
assumptions complicate the problem setting, and the
algorithms might not work well when these hard assumptions
do not hold.
Recent CNN-based deep learning approaches [6, 5, 42,
41, 19, 45] have demonstrated the robustness of the datadriven
approach. In particular, NeurVPS [45] provides a
framework to detect vanishing points in an end-to-end fashion
without relying on external heuristic line detectors. It
proposes conic convolution to exploit the geometric properties
of vanishing points by enforcing the feature extraction
and aggregation along the structural lines of vanishing
point candidates. This approach achieves satisfactory performance,
but it is inefficient as it requires evaluating all
possible vanishing points in an image (1FPS is reported in
[45]). In contrast, most vanishing point applications must
be run online in order to be useful in a practical setting.
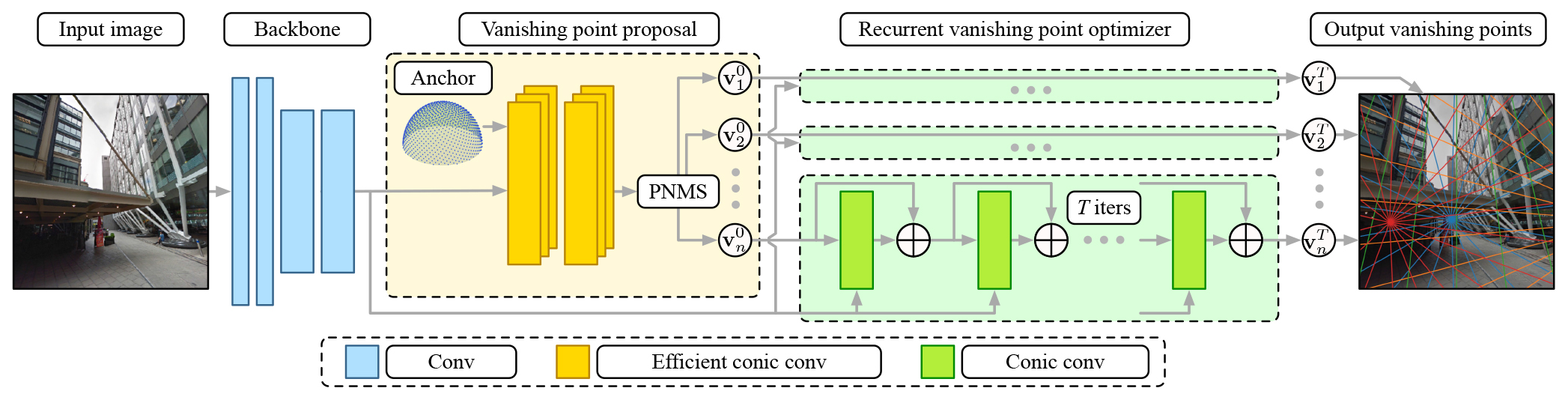
To this end, we introduce VaPiD, a novel end-to-end
rapid vanishing point detector that significantly boosts the
model efficiency using learned optimizers. VaPiD consists
of two components: (1) a vanishing point proposal network
(VPPN) that takes an image and returns a set of vanishing
point proposals. It harnesses a computation sharing scheme
to efficiently process dense vanishing point anchors; (2) a
neural vanishing point optimizer (NVPO) that takes each
proposal as input and optimizes for its position with a neural
network in an iterative fashion. In each iteration, it refines
the vanishing points by regressing the residuals and
updating the estimates. Our approach can be considered as
learning to optimize. Compared to the previous coarse-tofine
method in [45], our optimizing scheme avoids enumerating
all possible vanishing point candidate positions, which
largely improves the inference speed.
We comprehensively evaluate our method on four public
datasets including one synthetic dataset and three realworld
datasets. VaPiD significantly outperforms previous
works in terms of the efficiency, while achieving competitive,
if not better, accuracy compared with the baselines.
Remarkably, on the synthetic dataset, the cosine of the median
angle error (0.088°) is close to the machine epsilon
of 32-bit floating-point numbers1, which indicates that Va-
PiD pushes the detection accuracy to the limit of numerical
numbers. With fewer refinement iterations, VaPiD runs at
26 frames per second while maintaining a median angle error
of 0.145° for 512x512 images with 3 vanishing points.

Comparisons on Natural Scene. We show the comparisons on Natural Scene [47] in Tab. 2 and Fig. 7. Our method significantly outperforms the naive CNN classification and regression baselines as well as the contour-based clustering algorithm VPDet [47] in all metrics. It also outperforms the strong baseline NeurVPS [45] in most of the metrics. We note that the Natural Scene [47] is captured by cameras with different focal lengths. Such data favors the enumeration-based methods over the optimization-based methods, especially at a tighter angle threshold (i.e. below 1°). Nonetheless, we highlight that for images with one dominant vanishing point, VaPiD can run at real-time (43FPS) while maintaining competitive performance.
This paper presents a novel neural network-based vanishing points detection approach that achieves state-of-the-art performance while being significantly faster than previous works. Our method contains two designated modules: a novel vanishing points proposal network and a neural vanishing point optimizer. Our key insight is to use the computation sharing to accelerate massive convolution operations, and embrace a learning to optimize methodology that progressively learns the residual of the objectives. In future work, we will study how to combine VaPiD with downstream applications such as scene understanding, camera calibration, and camera pose estimation.