
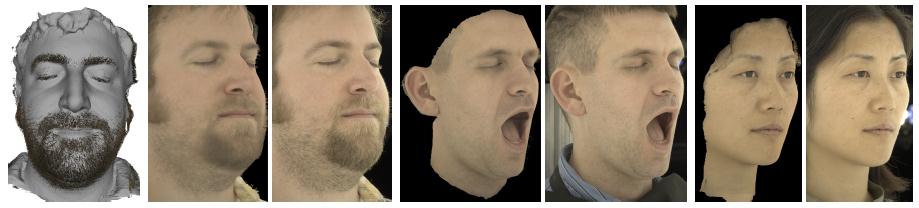
We propose an extension to multi-view face capture that reconstructs high quality facial hair automatically. Multi-view stereo is well known for producing high quality smooth surfaces and meshes, but fails on fine structure such as hair. We exploit this failure, and automatically detect the hairs on a face by careful analysis of the pixel reconstruction error of the multi-view stereo result. Central to our work is a novel stereo matching cost function, which we call equalized cross correlation, that properly accounts for both camera sensor noise and pixel sampling variance. In contrast to previous works that treat hair modeling as a synthesis problem based on image cues, we reconstruct facial hair to explain the same highresolution input photographs used for face reconstruction, producing a result with higher fidelity to the input photographs.
Modeling human hair from photographs is a topic of ongoing interest to the graphics
community. Yet, the literature is predominantly concerned with the hair volume on the
scalp, and it remains difficult to capture digital characters with interesting facial
hair. Recent stereo-vision-based facial capture systems (e.g. [Furukawa and Ponce 2010]
[Beeler et al. 2010]) are capable of capturing fine skin detail from high resolution
photographs, but any facial hair present on the subject is reconstructed as a blobby
mass. To create convincing digital characters, an artist typically has to remove the
offending geometry, and re-model the hair using artistic tools. Our primary goal in
this work is to automate the creation of facial hair for a face captured using multi-view
stereo, with high fidelity to the input photographs. Prior work in facial hair photo-modeling
is based on learned priors and image cues (e.g. [Herrera et al. 2010]), and does not
reconstruct the individual hairs belonging uniquely to the subject. We propose a method
for capturing the three dimensional shape of complex, multi-colored facial hair from a
small number of photographs taken simultaneously under uniform illumination. This
includes the hairs that make up the eyebrows, eyelashes, and any other relatively
trim facial hair present.
We analyze the pixel reconstruction errors in multi-view stereo, and observe that
errors are high on pixels where the subject is not well represented by a smooth mesh,
most notably around the hairs on the face. This arises from the typical assumption
in multi-view stereo, that the face may be reconstructed as a smooth polygonal mesh
with a texture map. We also note that the resolution obtained using readily available
camera equipment is capable of imaging individual facial hairs. This motivates our
approach, which is to reconstruct hairs that explain the pixels that could not be
explained using a smooth mesh. We also re-texture the parts of the mesh that lie
beneath the hair, obtaining a more complete model of the human face including facial
hair that results in a lower overall pixel reconstruction error.
Besides hair detection and reconstruction, we derive a novel stereo matching cost
function, which we call equalized cross correlation (Section 4.1). It is related
to normalized cross correlation but accounts for camera sensor noise and pixel
sampling variance. This allows us to discriminate between reconstruction error
caused by violation of the smooth mesh assumption versus that caused by noise.