
High-fidelity face digitization solutions often combine multi-view stereo (MVS) techniques for 3D reconstruction and a non-rigid registration step to establish dense correspondence across identities and expressions. A common problem is the need for manual clean-up after the MVS step, as 3D scans are typically affected by noise and outliers and contain hairy surface regions that need to be cleaned up by artists. Furthermore, mesh registration tends to fail for extreme facial expressions. Most learning-based methods use an underlying 3D morphable model (3DMM) to ensure robustness, but this limits the output accuracy for extreme facial expressions. In addition, the global bottleneck of regression architectures cannot produce meshes that tightly fit the ground truth surfaces. We propose ToFu, Topological consistent Face from multi-view, a geometry inference framework that can produce topologically consistent meshes across facial identities and expressions using a volumetric representation instead of an explicit underlying 3DMM. Our novel progressive mesh generation network embeds the topological structure of the face in a feature volume, sampled from geometry-aware local features. A coarse-to-fine architecture facilitates dense and accurate facial mesh predictions in a consistent mesh topology. ToFu further captures displacement maps for porelevel geometric details and facilitates high-quality rendering in the form of albedo and specular reflectance maps. These high-quality assets are readily usable by production studios for avatar creation, animation and physically-based skin rendering. We demonstrate state-of-the-art geometric and correspondence accuracy , while only taking 0.385 seconds to compute a mesh with 10K vertices, which is three orders of magnitude faster than traditional techniques. The code and the model are available for research purposes at Tianye Li's github.

Creating high-fidelity digital humans is not only highly
sought after in the film and gaming industry, but is also gaining
interest in consumer applications, ranging from telepresence
in AR/VR to virtual fashion models and virtual assistants.
While fully automated single-view avatar digitization
solutions exist [28, 29, 42, 56, 63], professional studios
still opt for high resolution multi-view images as input, to
ensure the highest possible fidelity and surface coverage in
a controlled setting [8, 23, 25, 40, 41, 46, 50] instead of unconstrained
input data. Typically, high-resolution geometric
details
(< 1mm error) are desired along with high resolution
physically-based material properties (at least 4K). Furthermore,
to build a fully rigged face model for animation, a
3824 large number of facial scans and alignments (often over 30)
are performed, typically following some conventions based
on the Facial Action Coding System (FACS).
A typical approach used in production consists of using
a multi-view stereo acquisition process to capture detailed
3D scans of each facial expression, and a non-rigid registration
[8, 36] or inference method [37] is used to warp a
3D face model to each scan in order to ensure consistent
mesh topology. Between these two steps, manual clean-up
is often necessary to remove artifacts and unwanted surface
regions, especially those with facial hair (beards, eyebrows)
as well as teeth and neck regions. The registration process
is often assisted with manual labeling tasks for correspondences
and parameter tweaking to ensure accurate fitting. In
a production setting, a completed rig of a person can easily
take up to a week to finalize.
Several recent techniques have been introduced to automate
this process by fitting a 3D model directly to a calibrated
set of input images. The multi-view stereo face modeling
method of [21] is not only particularly slow, but relies
on dynamic sequences and carefully tuned parameters for
each subject to ensure consistent parameterization between
expressions. In particular facial expressions that are not
captured continuously cannot ensure accurate topological
consistencies. More recent deep learning approaches [4, 63]
use a 3D morphable model (3DMM) inference to obtain a
coarse initial facial expression, but require a refinement step
based on optimization to improve fitting accuracy. Those
methods are limited in fitting extreme expressions due to
the constraints of linear 3DMMs and fitting tightly to the
ground-truth face surfaces due to the global nature of their
regression architectures. The additional photometric refinement
also tends to fit unwanted regions like facial hair.
We introduce a new volumetric approach for consistent
3D face mesh inference using multi-view images. Instead
of relying explicitly on a mesh-based face model such as
3DMM, our volumetric approach is more general, allowing
it to capture a wider range of expressions and subtle deformation
details on the face. Our method is also three orders
of magnitude faster than conventional methods, taking only
0.385 seconds to generate a dense 3D mesh (10K vertices)
as well as produce additional assets for high-fidelity production
use cases, such as albedo, specular, and high-resolution
displacement maps.
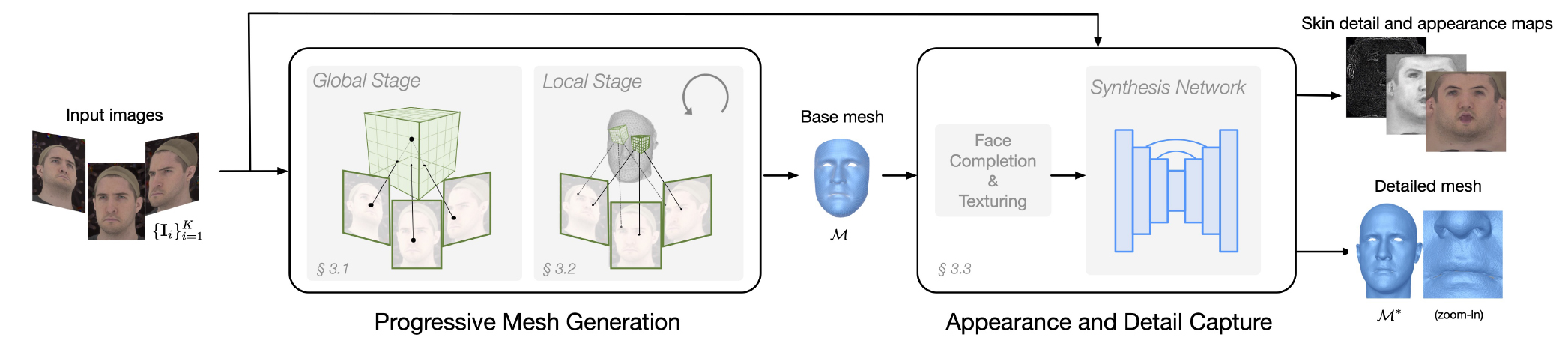
To this end, we propose a progressive mesh generation
network that can infer a topologically consistent mesh directly.
Our volumetric architecture predicts vertex locations
as probability distributions, along with volumetric features
that are extracted using the underlying multi-view geometry.
The topological structure of the face is embedded into
this architecture using a hierarchical mesh representation
and coarse-to-fine network.
Our experiments show that ToFu is capable of producing
highly accurate geometry consistent with topology automatically,
while existing methods either rely on manual
clean-up and parameter tuning, or are less accurate especially
for subjects with facial hair. Since we can ensure a
consistent parameterization across facial identities and expressions
without any human input, our solution is suitable
for scaled digitization of high-fidelity facial avatars, We
not only reduce the turn around time for production, but
is also provide a critical solution for generating large facial
datasets, which is often associated with excessive manual
labor. Our main contributions are:
Face Capture. Traditionally, face acquisition is separated
into two steps, 3D face reconstruction and registration [17].
Facial geometry can be captured with laser scanners [35],
passive Multi-View Stereo (MVS) capture systems [7], dedicated
active photometric stereo systems [23, 41], or depth
sensors based on structured light or time-of-flight sensors.
Among these, MVS is the most commonly used
[18, 20, 24, 34, 43, 60]. Although these approaches produce
high-quality geometry, they suffer from heavy computation
due to the pairwise features matching across views, and they
tend to fail in case of sparse view inputs due to the lack of
overlapping neighboring views. More recently, deep neural
networks learn multi-view feature matching for 3D geometry
reconstruction [26, 31, 33, 51, 64]. Compared to classical
MVS methods, these learning based methods represent
a trade-off between accuracy and efficacy. All these MVS
methods output unstructured meshes, while our method produces
meshes in dense vertex correspondence.
Most registration methods use a template mesh and fit
it to the scan surface by minimizing the distance between
the scan’s surface and the template. For optimization, the
template mesh is commonly parameterized with a statistical
shape space [3, 9, 11, 38] or a general blendshape basis [48].
Other approaches directly optimize the vertices of the template
mesh using a non-rigid Iterative Closest Point (ICP)
[36], with a statistical model as regularizer [39], or jointly
optimize correspondence across an entire dataset in a groupwise
fashion [12, 65]. For a more thorough review of face
acquisition and registration, see Egger et al. [17]. All these
registration methods solve for facial correspondence independent
from the data acquisition. Therefore, errors in the
raw scan data propagate into the registration.
Only few methods exist that are similar to our method
of directly outputting high-quality registered 3D faces from
calibrated multi-view input [8, 13, 14, 21]. While sharing a
similar goal, our method goes beyond these approaches in
several significant ways. Unlike our method, they require
calibrated multi-view image sequence input, contain multiple
optimization steps (e.g. for building a subject specific
template [21], or anchor frame meshes [8]), and are computationally
slow (e.g. 25 minutes per frame for the coarse
mesh reconstruction [21]). ToFu instead takes calibrated
multi-view images as input (i.e. static) and directly outputs
a high-quality mesh in dense vertex correspondence in
0.385 seconds. Regardless, our method achieves stable reconstruction
and registration results for sequence input.
We introduced a 3D face inference approach from multiview input images that can produce high-fidelity 3D faces meshes with consistent topology using a volumetric sampling approach. We have shown that, given multi-view inputs, implicitly learning a shape variation and deformation field can produce superior results, compared to methods that use an underlying 3DMM even if they refine the resulting inference with an optimization step. We have demonstrated sub-millimeter surface reconstruction accuracy, and stateof- the-art correspondence performance while achieving up to 3 orders of magnitude of speed improvement over conventional techniques. Most importantly, our approach is fully automated and eliminates the need for data clean up after MVS, or any parameter tweaking for conventional nonrigid registration techniques. Our experiments also show that the volumetric feature sampling can aggregate effectively features across views at various scales and can also provide salient information for predicting accurate alignment without the need for any manual post-processing. Our next step is to extend our approach to regions beyond the skin region, including teeth, tongue, and eyes. We believe that our volumetric digitization framework can handle nonparametric facial surfaces, which could potentially eliminate the need for specialized shaders and models in conventional graphics pipelines. Furthermore, we would like to explore video sequences, and investigate ways to ensure temporal coherency in fine-scale surface deformations. Our model is suitable for articulated non-rigid objects such as human bodies, which motivates us to look into more general shapes and objects such as clothing and hair.