

Photo-realistic face avatar capture has become a key element in
entertainment media due to the realism and immersion it enables.
As the digital assets created from photos of human faces surpass
their artist-created counterparts in both diversity and naturalness,
there are increasing demands for the digitized face avatars in the
majority of the sectors in the digital industry: movies, video games,
teleconference, and social media platforms, to name a few. In a studio
setting, the term “avatar” encompasses several production standards
for a scanned digital face, including high-resolution geometry (
with pore-level details), high-resolution facial textures (4K) with
skin reflectance measurements, as well as a digital format that is
consistent in mesh connectivity and ready to be rigged and animated.
These standards together are oftentimes referred to as a production-ready face avatar.
In this paper, we consider a common face acquisition setting
where a collection of calibrated cameras capture the color images
that are processed into a full set of assets for a face avatar.
In general, today’s professional setting employs a two-step approach to
the creation of the face assets. The first step computes a
middle-frequency geometry of the face (with noticeable wrinkle and facial
muscle movement) from multi-view stereo (MVS) algorithms. A
second registration step is then taken to register the geometries
to a template meth connectivity, commonly of lower resolution
with around 10k to 50k vertices. For production use, the registered
base mesh is augmented by a set of texture maps, composed of
albedo, specular and displacement maps, that are computed via
photogrammetry cues and specially designed devices (e.g. polarizers
and gradient light patterns in [Ghosh et al. 2011a; Ma et al. 2008]).
The lower-resolution base mesh is combined with a high resolution
displacement maps to represent geometry with pore, freckle-level
details. Modern physically-based rendering agents further utilize
the albedo and specularity maps to render the captured face in
photo-realistic quality.

3.1 Capture System Setup
Our training data is acquired by a Light Stage scan system, which
is able to capture at pore-level accuracy in both geometry and
reflectance maps by combining photometric stereo reconstruction
[Ghosh et al. 2011b] and polarization promotion [LeGendre et al.
2018]. The camera setup consists of 25 Ximea machine vision
cameras, including 17 monochrome and 8 color cameras. The
monochrome cameras, compared to their color counterparts, support
more efficient and higher-resolution capturing, which are essential
for sub-millimeter geometry details, albedo, and specular reflectance
reconstruction. The additional color cameras aid in stereo-based
mesh reconstruction. The RGB colors in the captured images are
obtained by adding successive monochrome images recorded under
different illumination colors as shown in [LeGendre et al. 2018]. We
selected a FACS set [Ekman and Friesen 1978] which combines 40
action units to a condensed set of 26 expressions for each subjects
to perform. A total number of 64 subjects, ranging from age 18 to
67, were scanned.
3.2 Data Preparation
Starting from the multi-view images, we first reconstruct the
geometry of the scan with neutral expression of the target subject
using a multi-view stereo (MVS) algorithm. Then the reconstructed
scans are registered using a linear fitting algorithm based on a 3D
face morphable model, similar to the method in [Blanz and Vetter
1999]. In particular, we fit the scan by estimating the morphable
model coefficients using linear regression to obtain an initial shape
in the template topology. Then a non-rigid Laplacian deformation
is performed to further minimize the surface-to-surface distance.
We deform all the vertices on the initially fitted mesh by setting the
landmarks to match their correspondence on the scan surface as
data terms and use the Laplacian of the mesh as a regularization
term.
We adopt and implement a variation of [Sorkine et al. 2004] to
solve this system. Once the neutral expression of the target person
is registered, the rest of the expressions are processed based on it.
We first adopted a set of generic blendshapes (a set of vertex
differences computed between each expression and the neutral, with
54 predefined orthogonal expressions ) and the fitted neutral base
mesh to fit the scanned expressions and then performed the same
non-rigid mesh registration step to further minimize the fitting
error. Additionally, to ensure the cross-expression consistency for
the same identity, optical flow from neutral to other expressions is
added as a dense consistency constraint in the non-rigid Laplacian
deformation step. This 2D optical flow will be further used as a
projection constraint when solving for the 3D location of a vertex
on the target expression mesh during non-linear deformation.
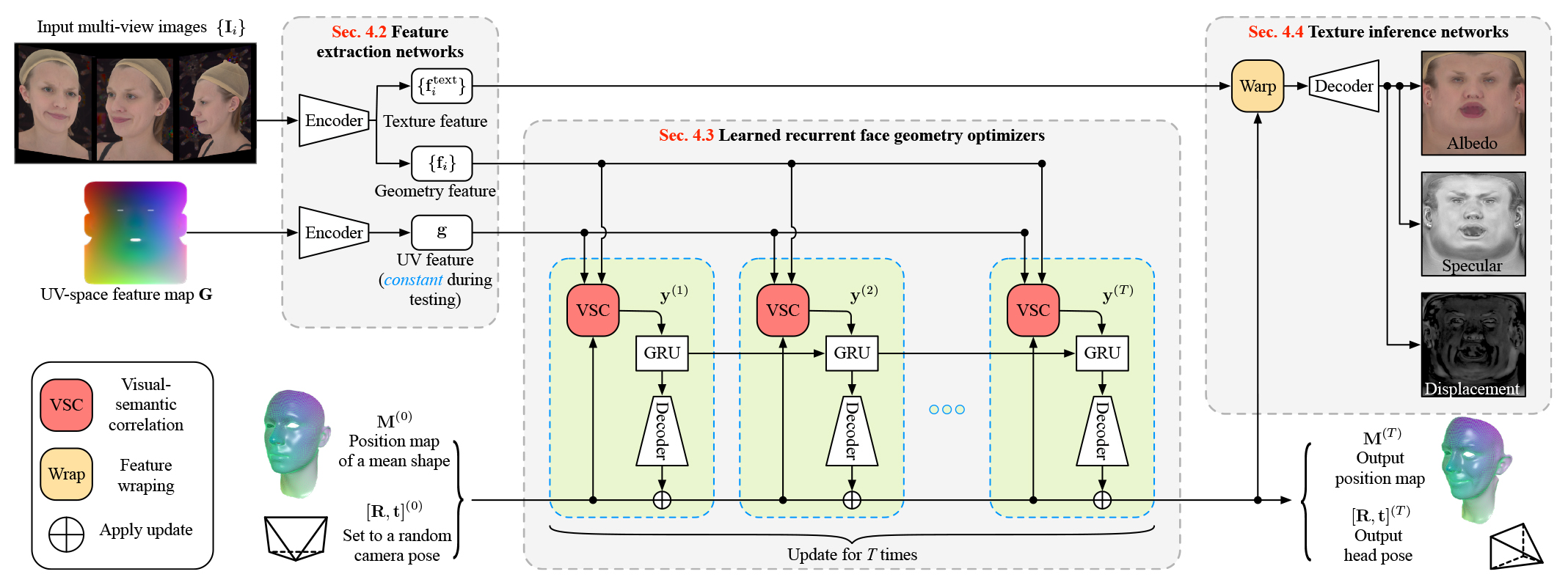
All the processed geometries and textures share the same mesh
connectivity and thus have dense vertex-level correspondence. The
diffuse-specular separation is computed under a known spherical
illumination [Ma et al. 2007]. The pore-level details of the geometry
are computed by employing albedo and normal maps in the stereo
reconstruction [Ghosh et al. 2011b] and represented as displacement
maps to the base mesh. The full set of the generic model consists
of a base geometry, a head pose, and texture maps (albedo, specular
intensity, and displacement) encoded in 4𝐾 resolution. 3D vertex
positions are rasterized to a three-channel HDR bitmap of 256 × 256
pixels resolution to enable joint learning of the correlation between
geometry and albedo. 15 camera views are used for the default
setting to infer the face assets with our neural network. Figure 2
shows an example of captured multi-view images and a full set of
our processed face asset that is used for training.
In addition to the primary assets generated using our proposed network, we may
also assemble secondary components (e.g., eyeballs, lacrimal fluid,
eyelashes, teeth, and gums) to the network-created avatar. Based on
a set of handcrafted blendshapes with all the primary and secondary
parts, we linearly fit the reconstructed mesh by computing the
blending weights that drive the secondary components to travel
with primary parts, such that the eyelashes will travel with eyelids.
Except for the eyeball, other secondary parts share a set of generic
textures for all the subjects. For eyeball, we adopt an eyeball assets
database [Kollar 2019] with 90 different pupil patterns to match
with input subjects. Note that all the eyes share the same shape as
in [Kollar 2019] and in our database. For visualization purposes, we
manually pick the matching eye color. The dataset is split into 45
subjects for the training and 19 for the evaluation. Each set of capture
contains a neutral face and 26 expressions, including extreme face
deformation, asymmetrical motions, and subtle expressions.

Figure 6 shows the rendered results using the complete set of assets
produced by our system from randomly selected testing data,
including the input reference images, the directly inferred texture maps,
and the renderings under different illuminations. In addition,
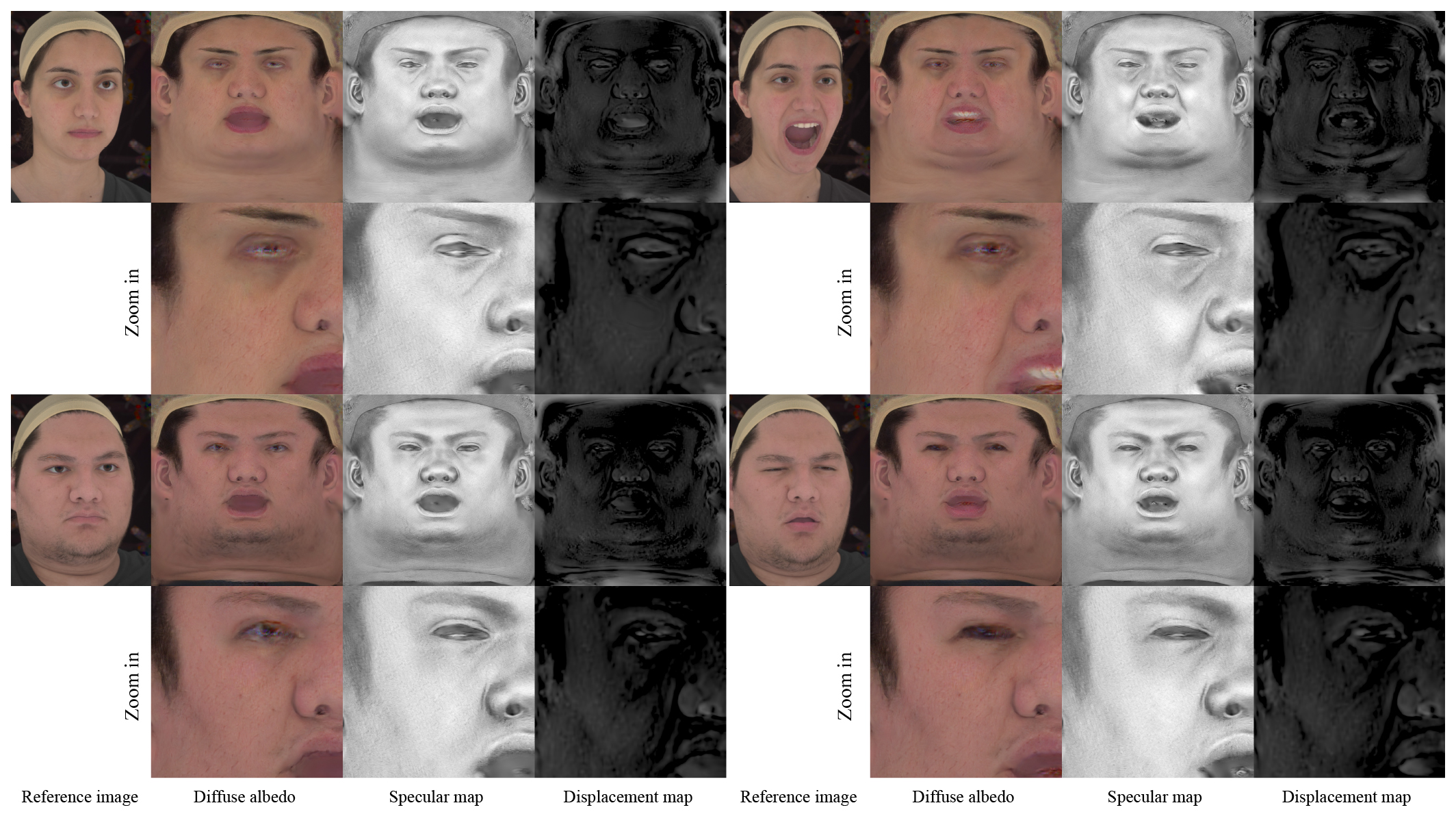
Figure 7 shows a detailed visualization of the inferred high-resolution
texture maps: diffuse albedo, specular and displacement map. All
results are rendered using the reconstructed geometries and
texture maps with Maya Arnold using a physically-based shader under
environment illumination provided by HDRI images.
In the following sections, we provide comparative evaluation
to directly related baseline methods (Section 6.1) as well as an
ablation study (Section 6.2). In addition, we also demonstrate three
meaningful applications that ReFA enables in Section 6.3.
To quantitatively evaluate the geometry reconstruction, we first convert our inferred position map to a mesh representation as described in section 4.1. We then compute the scan-to-mesh errors using a method that follow [Li et al. 2021], with the exception that the errors are computed on a full face region including the ears. We measure both the mean and median errors as the main evaluation metrics, given that the two statistics capture the overall accuracy of the reconstruction models. To better quantize the errors for analysis, we additionally show the Cumulative Density Function (CDF) curves of the errors, which measure the percentage of point errors that falls into a given error threshold.