
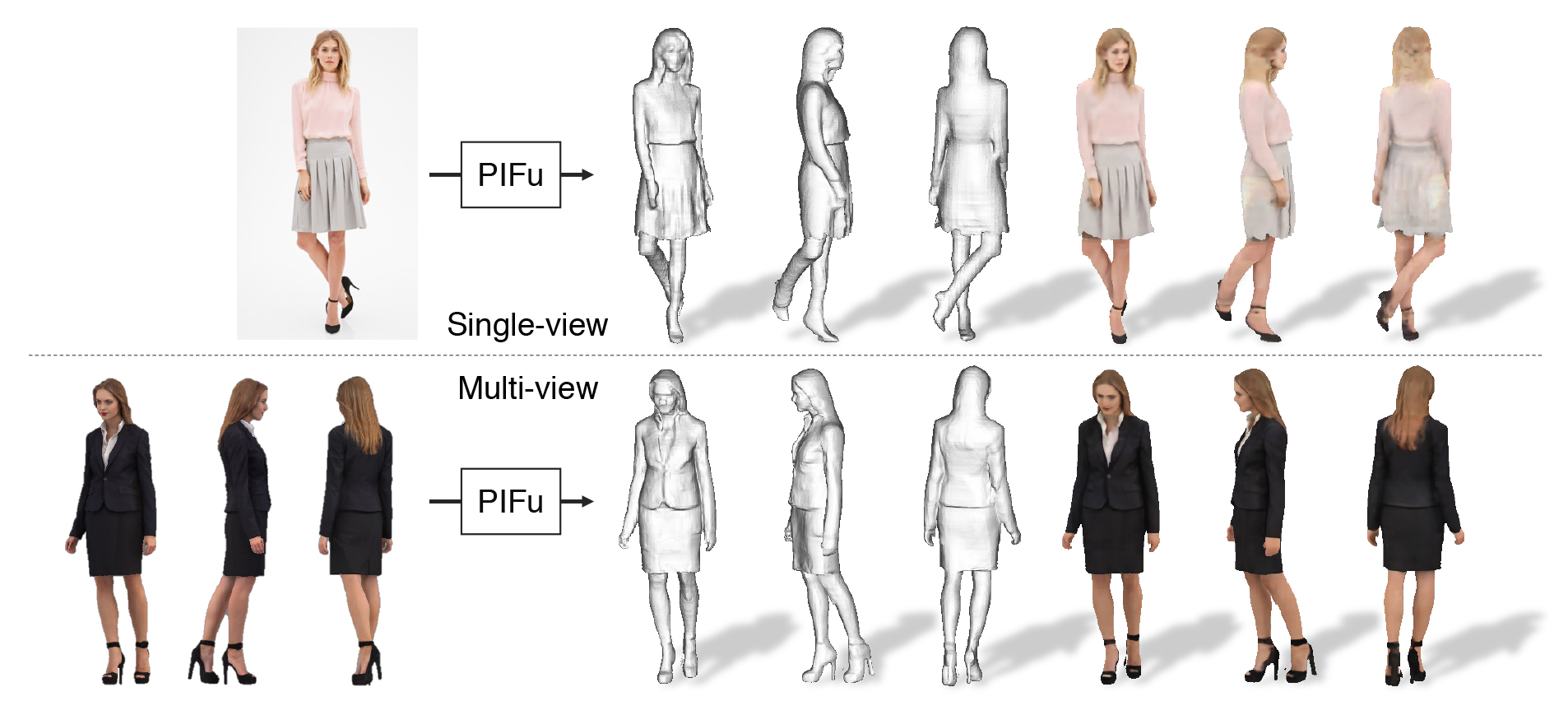
We introduce Pixel-aligned Implicit Function (PIFu), a highly effective implicit representation that locally aligns pixels of 2D images with the global context of their corresponding 3D object. Using PIFu, we propose an endto-end deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture from a single image, and optionally, multiple input images. Highly intricate shapes, such as hairstyles, clothing, as well as their variations and deformations can be digitized in a unified way. Compared to existing representations used for 3D deep learning, PIFu can produce high-resolution surfaces including largely unseen regions such as the back of a person. In particular, it is memory efficient unlike the voxel representation, can handle arbitrary topology, and the resulting surface is spatially aligned with the input image. Furthermore, while previous techniques are designed to process either a single image or multiple views, PIFu extends naturally to arbitrary number of views. We demonstrate high-resolution and robust reconstructions on real world images from the DeepFashion dataset, which contains a variety of challenging clothing types. Our method achieves state-of-the-art performance on a public benchmark and outperforms the prior work for clothed human digitization from a single image. The project website can be found here
In an era where immersive technologies and
sensorpacked autonomous systems are becoming increasingly
prevalent, our ability to create virtual 3D content at scale
goes hand-in-hand with our ability to digitize and understand
3D objects in the wild. If digitizing an entire object in
3D would be as simple as taking a picture, there would be
no need for sophisticated 3D scanning devices, multi-view
stereo algorithms, or tedious capture procedures, where a
sensor needs to be moved around.
For certain domain-specific objects, such as faces, human
bodies, or known man made objects, it is already possible
to infer relatively accurate 3D surfaces from images with
the help of parametric models, data-driven techniques, or
deep neural networks. Recent 3D deep learning advances
have shown that general shapes can be inferred from very
few images and sometimes even a single input. However,
the resulting resolutions and accuracy are typically limited,
due to ineffective model representations, even for domain
specific modeling tasks.
We evaluate our proposed approach on a variety of datasets, including RenderPeople and BUFF, which has ground truth measurements, as well as DeepFashion which contains a diverse variety of complex clothing.
Hao Li is affiliated with the University of Southern California, the USC Institute for Creative Technologies, and Pinscreen. This research was conducted at USC and was funded by in part by the ONR YIP grant N00014-17-S-FO14, the CONIX Research Center, one of six centers in JUMP, a Semiconductor Research Corporation program sponsored by DARPA, the Andrew and Erna Viterbi Early Career Chair, the U.S. Army Research Laboratory under contract number W911NF-14-D-0005, Adobe, and Sony. This project was not funded by Pinscreen, nor has it been conducted at Pinscreen or by anyone else affiliated with Pinscreen. Shigeo Morishima is supported by the JST ACCEL Grant Number JPMJAC1602, JSPS KAKENHI Grant Number JP17H06101, the Waseda Research Institute for Science and Engineering. Angjoo Kanazawa is supported by the Berkeley Artificial Intelligence Research sponsors. The content of the information does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.