
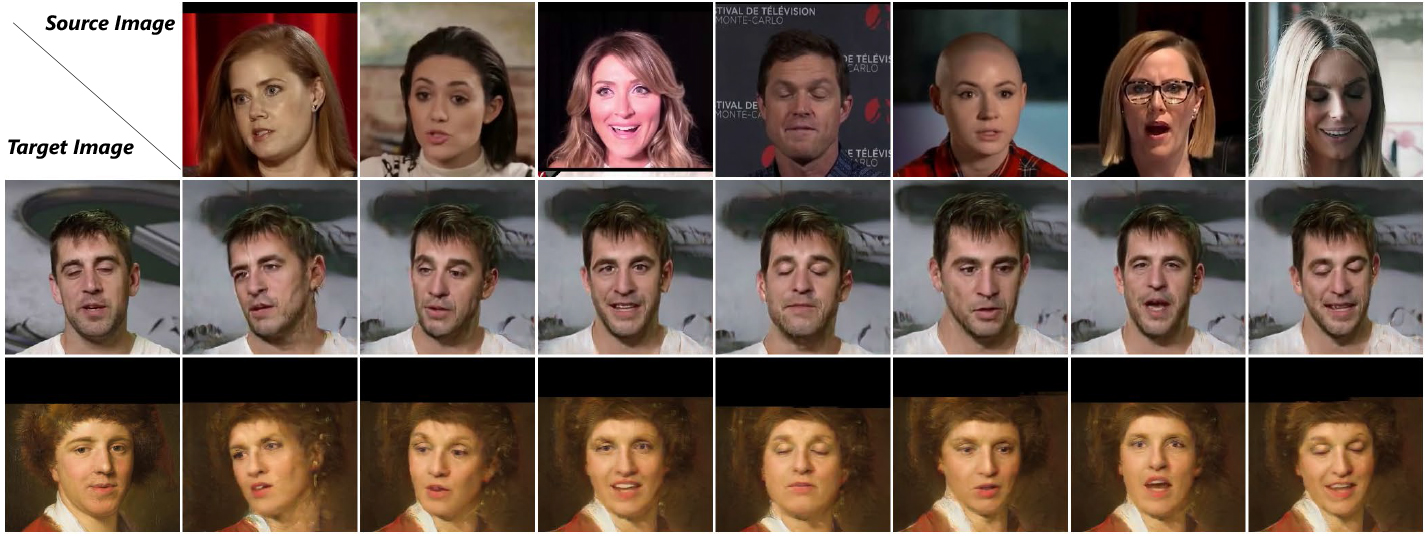
We present a deep learning-based framework for portrait reenactment from a single picture of a target (one-shot) and a video of a driving subject. Existing facial reenactment methods suffer from identity mismatch and produce inconsistent identities when a target and a driving subject are different (cross-subject), especially in one-shot settings. In this work, we aim to address identity preservation in cross-subject portrait reenactment from a single picture. We introduce a novel technique that can disentangle identity from expressions and poses, allowing identity preserving portrait reenactment even when the driver's identity is very different from that of the target. This is achieved by a novel landmark disentanglement network (LD-Net), which predicts personalized facial landmarks that combine the identity of the target with expressions and poses from a different subject. To handle portrait reenactment from unseen subjects, we also introduce a feature dictionary-based generative adversarial network (FD-GAN), which locally translates 2D landmarks into a personalized portrait, enabling one-shot portrait reenactment under large pose and expression variations. We validate the effectiveness of our identity disentangling capabilities via an extensive ablation study, and our method produces consistent identities for cross-subject portrait reenactment. Our comprehensive experiments show that our method signifcantly outperforms the state-of-the-art single-image facial reenactment methods. We will release our code and models for academic use.
Disentangling landmarks into identity and pose/expression is difficult due to the
lack of accurate numerical labeling for pose/expression. Inspired by [1], which
can disentangle two complementary factors of variations with only one of them
labeled, we propose a landmark disentanglement network (LD-Net) to disentangle
identity and pose/expression using data with only the subject's identity
labeled. More importantly, our network generalizes well to novel identities (i.e.,
those unseen during training), unlike previous works (e.g. [1]).
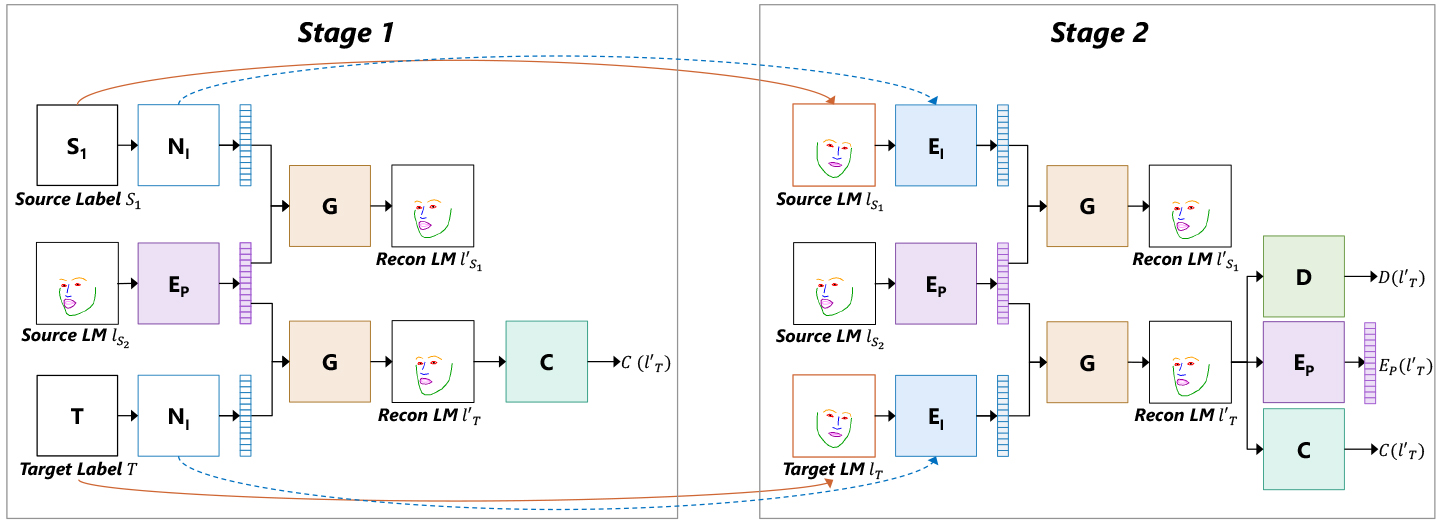
Given 2D facial landmarks from a pair of face images, LD-Net first disentangles
the landmarks into a pose/expression latent code and an identity latent
code, then combines the target's identity code with the source's pose/expression
code to synthesize new landmarks. As shown in Fig. 3, the training procedure of
LD-Net is divided into two stages. Stage 1 aims to train a stable pose/expression
encoder and Stage 2 generalizes to predict an identity code from landmarks instead
of using identity labels so as to handle unseen identities.
We first conduct an evaluation and ablation study in Sec. 4.1 on the performance
of LD-Net and FD-GAN independently, followed by comparisons of our
full method with the state-of-the-art methods on cross-subject face reenactment
in Sec. 4.2. For more results tested on unconstrained portrait images, please refer
to the supplemental material.
Implementation details. For FD-GAN, the extractor and translator are based on
U-Nets, with both networks joined together by dictionary writer/reader modules
inserted into the up-convolution modules. The discriminator and classifier for
FD-GAN are patch-based and have the same structure as the down-convolution
part of the U-Nets. Please refer to the supplemental material for more details
concerning the network structures and training strategies.
Performance. Our method takes approximately 0.08s for FD-GAN to generate
one image and 0.02s for LD-Net to perform landmark disentanglement on a
single NVIDIA TITAN X GPU.
Training datasets. The training dataset is built from VoxCeleb video training
data [13] which is processed by dlib [36] to crop a 256x256 face image at 25fps
and to extract its landmarks. In total, it contains 52,112 videos for 1,000 ran-
domly selected subjects.

We have demonstrated a technique for portrait reenactment that only requires a
single target picture and 2D landmarks of the target and the driver. The resulting
portrait is not only photorealistic but also preserves recognizable facial features
of the target. Our comparison shows significantly improved results compared
to state-of-the-art single-image portrait manipulation methods. Our extensive
evaluations confirm that identity disentanglement of 2D landmarks is effective
in preserving the identity when synthesizing a reenacted face. We have shown
that our method can handle a wide variety of challenging facial expressions and
poses of unseen identities without subject-specific training. This is made possible
thanks to our generator, which uses a feature dictionary to translate landmark
features into a photorealistic portrait.
A limitation of our method is that the resulting portrait has only a resolution
of 256x256, and it is still difficult to capture high-resolution person-specific
details such as stubble hair. It could also suffer from some artifacts for non-facial
parts and the background region, since we rely on the landmarks to transfer
facial appearance but the landmarks contain no structural information about
the hair or background. We believe such a limitation could be further addressed
by incorporating dense pixel-wise conditioning [40] and segmentation. While our
method can produce reasonably stable portrait reenactment results from a frame
of target and 2D landmarks, the temporal consistency could be further improved
by taking into account temporal information from the entire video.