
Learning latent representations of registered meshes is useful for many 3D tasks. Techniques have recently shifted to neural mesh autoencoders. Although they demonstrate higher precision than traditional methods, they remain unable to capture fine-grained deformations. Furthermore, these methods can only be applied to a template-specific surface mesh, and is not applicable to more general meshes, like tetrahedrons and non-manifold meshes. While more general graph convolution methods can be employed, they lack performance in reconstruction precision and require higher memory usage. In this paper, we propose a non-template-specific fully convolutional mesh autoencoder for arbitrary registered mesh data. It is enabled by our novel convolution and (un)pooling operators learned with globally shared weights and locally varying coefficients which can efficiently capture the spatially varying contents presented by irregular mesh connections. Our model outperforms state-of-the-art methods on reconstruction accuracy. In addition, the latent codes of our network are fully localized thanks to the fully convolutional structure, and thus have much higher interpolation capability than many traditional 3D mesh generation models.
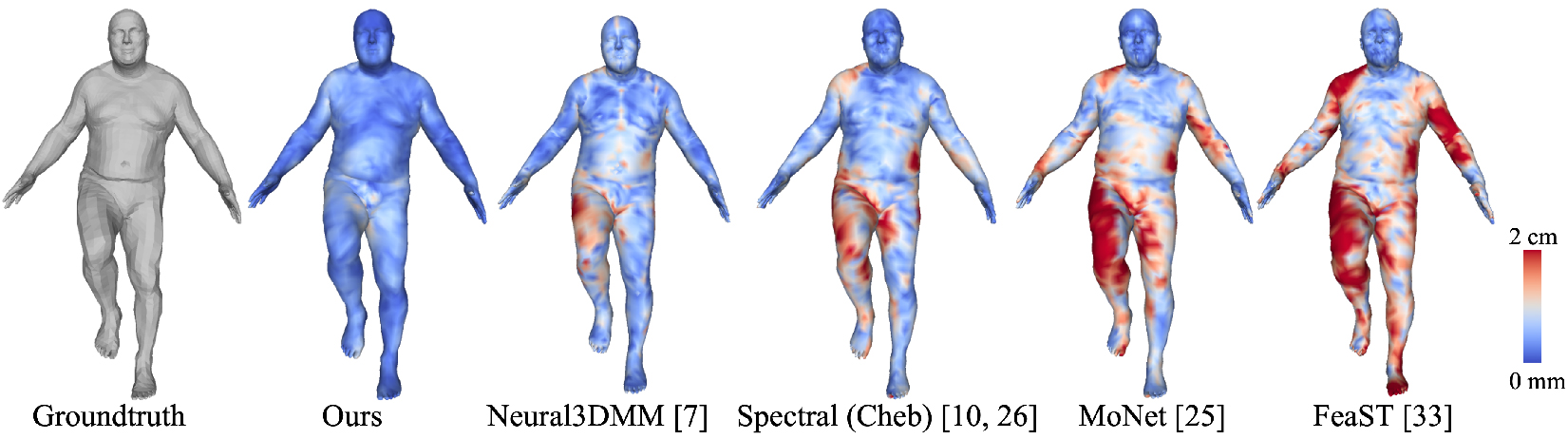
We first experimented on the 2D-manifold D-FAUST human body dataset [4]. It contains 140
sequences of registered human body meshes. We used 103 sequences (32933 meshes in total) for
training, 13 sequences (4023 meshes) for validation and 13 sequences (4264 meshes) for testing. Our
AE has a mean test error at 5.01 mm after 300 epochs of training.
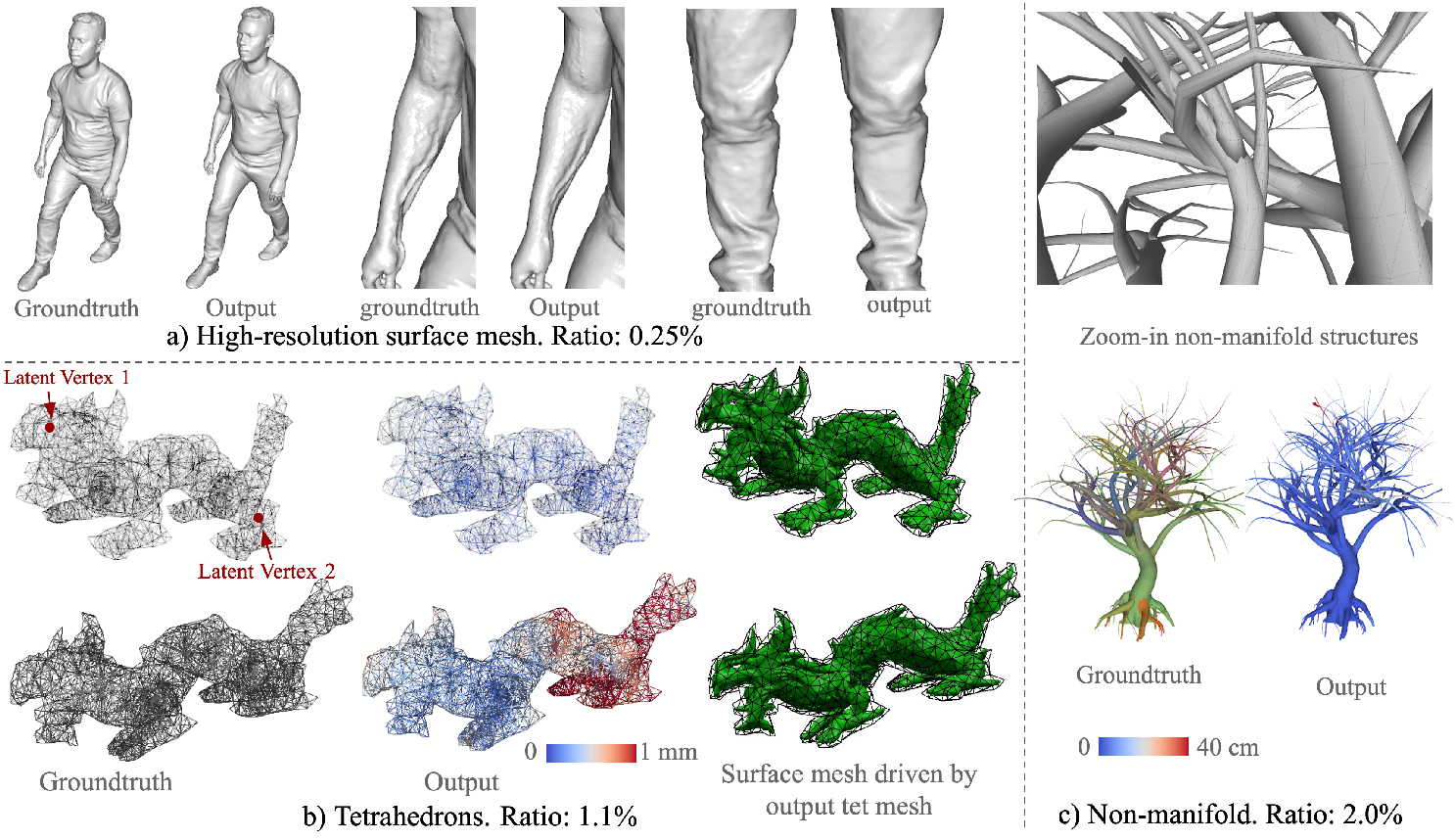
Then we tested for the 3D-manifold cases using 3D tetrahedrons (tet meshes) (Figure 3b). Tet
meshes are commonly used for physical simulation [3]. We used a dataset containing 10k deformed
tet meshes of an Asian dragon and use 7k for training an AE, 1.3k for validation and 562 for testing.
After 400 epochs of training, the error converged to 0.2 mm.
To demonstrate our model on non-manifold data, we trained the network on a 3D tree model with
non-manifold components 3 (Figure 3c). We made a dataset of 10 sequences of this tree’s animation
simulated by Vega using random forces, 1000 frames for each clip, and used 2 clips for testing, 2
clips for validation and the rest for training. After 36 epochs, the reconstruction error dropped to 4.1
cm.
3D data in real applications can have very high resolution. Therefore, we experimented our network
on a high-resolution human dataset that contains 24,628 fully aligned meshes, each with 154k vertices
and 308k triangles. We randomly chose 2; 463 for testing and used the rest for training. The AE’s
bottleneck contains 18 vertices and 64 dimensions per vertex, resulting in a compression rate of
0.25%. After training 100 epochs, the mean test error dropped to 3:01 mm. From Figure 3a we can
see that the output mesh is quite detailed. Compared with the groundtruth, which is more noisy, the
network output is relatively smoothed. Interestingly, from the middle two images, we can see that
the network learned to reconstruct the vein in the inner side of the arm which is missing from the
originally noisy surface.
We demonstrate localized latent feature interpolation with an AE trained on hand meshes. As in
Figure 6, we set the latent vertices to be at the tips of the five fingers and the wrist. For interpolation,
we first inferred the latent codes from a source mesh and a target mesh, then we linearly interpolated
the latent code on each individual latent vertex separately. With only two input hand models, we can
obtain many more gestures by interpolating a subset of latent vertices instead of the entire code.
We further demonstrate the reconstruction result by mixing local latent features of two D-FAUST
models. As shown in Figure 5, we replace "Man A’s" latent code which corresponds to the foot area
with "Man B’s" foot latent code. The result is Man A with a new foot pose, while keeping the rest of
Man A the same. In particular, note that Man A’s new leg pose is still "his" leg, and not "Man B’s"
leg. This shows that we can in fact perform reasonable pose transfer even using different identities.
We introduce a novel mesh AE that produces SOTA results for regressing arbitrary types of registered
meshes. Our method contains natural analogs of the operations in classic 2D CNNs while avoiding
the high parameter cost of naive locally connected networks by using a shared kernel basis. It is also
the first mesh AE that demonstrates localized interpolation.
Several future directions are possible with our formulation. For one thing, though our method can
learn on arbitrary graphs, all the graphs in the dataset must have the same topology. Thus, it requires
that the mesh connectivity is already solved in the training set. In the future, we plan to extend our
work so that it can work on datasets with varying topology.