
We present an interactive approach to synthesizing realistic variations in facial hair in images, ranging from subtle edits to existing hair to the addition of complex and challenging hair in images of clean-shaven subjects. To circumvent the tedious and computationally expensive tasks of modeling, rendering and compositing the 3D geometry of the target hairstyle using the traditional graphics pipeline, we employ a neural network pipeline that synthesizes realistic and detailed images of facial hair directly in the target image in under one second. The synthesis is controlled by simple and sparse guide strokes from the user defining the general structural and color properties of the target hairstyle. We qualitatively and quantitatively evaluate our chosen method compared to several alternative approaches. We show compelling interactive editing results with a prototype user interface that allows novice users to progressively refine the generated image to match their desired hairstyle, and demonstrate that our approach also allows for flexible and high-fidelity scalp hair synthesis.

Hair is a crucial component for photorealistic avatars and CG characters. In professional production, human hair is modeled and rendered with sophisticated devices and tools [11, 39, 69, 73]. We refer to [66] for an extensive survey of hair modeling techniques. In recent years, several multi-view [51, 29] and single-view [9, 8, 30, 7] hair modeling methods have been proposed. An automatic pipeline for creating a full head avatar from a single portrait image has also been proposed [31]. Despite the large body of work in hair modeling, however, techniques applicable to facial hair reconstruction remain largely unexplored. In [3], a coupled 3D reconstruction method is proposed to recover both the geometry of sparse facial hair and its underlying skin surface. More recently, Hairbrush [71] demonstrates an immersive data-driven modeling system for 3D strip-based hair and beard models.
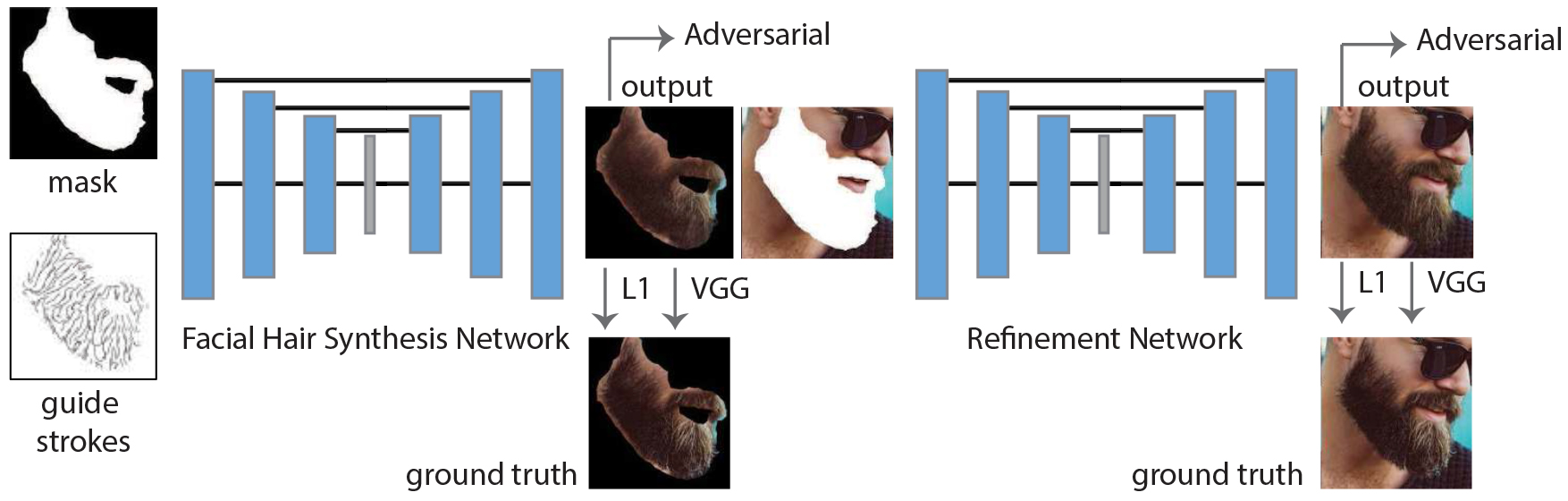
Once the initial facial hair region is synthesized, we perform refinement and
compositing into the input image. This is achieved by a second
encoder-decoder network. The input to this network is the
output of the initial synthesis stage, the corresponding
segmentation map, and the segmented target image (the target
image with the region to be synthesized covered by the segmentation mask).
The output is the image with the synthesized facial hair refined and composited into it.
The architecture of the second generator and discriminator
networks are identical to the first network, with only the
input channel sizes adjusted accordingly. While we use the
adversarial and perceptual losses in the same manner as the
previous stage, we define the L1 loss on the entire
synthesized image. However, we increase the weight of this loss
by a factor of 0.5 in the segmented region containing the
facial hair. The boundary between the synthesized facial hair
region and the rest of the image is particularly important for
plausible compositions. Using erosion/dilation operations
on the segmented region (with a kernel size of 10 for each
operation), we compute a mask covering this boundary. We
further increase the weight of the loss for these boundary
region pixels by a factor of 0.5. More details on the training
process can be found in the appendix.

While we demonstrate impressive results, our approach
has several limitations. As with other data-driven algorithms,
our approach is limited by the amount of variation
found in the training dataset. Close-up images of highresolution
complex structures fail to capture all the complexity
of the hair structure, limiting the plausibility of the
synthesized images. As our training datasets mostly
consist of images of natural hair colors, using input with very
unusual hair colors also causes noticeable artifacts. See
Fig. 10 for examples of these limitations.
We demonstrate that our approach, though designed to
address challenges specific to facial hair, synthesizes
compelling results when applied to scalp hair given appropriate
training data. It would be interesting to explore how well
this approach extends to other related domains such as animal
fur, or even radically different domains such as editing
and synthesizing images or videos containing fluids or other
materials for which vector fields might serve as an
appropriate abstract representation of the desired image content.