
We present a learning-based method for estimating 4D reflectance field of a person given video footage illuminated under a flat-lit environment of the same subject. For training data, we use one light at a time to illuminate the subject and capture the reflectance field data in a variety of poses and viewpoints. We estimate the lighting environment of the input video footage and use the subject’s reflectance field to create synthetic images of the subject illuminated by the input lighting environment. We then train a deep convolutional neural network to regress the reflectance field from the synthetic images. We also use a differentiable renderer to provide feedback for the network by matching the relit images with the input video frames. This semi-supervised training scheme allows the neural network to handle unseen poses in the dataset as well as compensate for the lighting estimation error. We evaluate our method on the video footage of the real Holocaust survivors and show that our method outperforms the state-of-the-art methods in both realism and speed.

The New Dimensions in Testimony project at the University
of Southern California’s Institute for Creative Technologies
recorded extensive question-and-answer interviews
with twelve survivors of the World War II Holocaust.
Each twenty-hour interview, conducted over five days, produced
over a thousand responses, providing the material
for time-offset conversations through AI based matching
of novel questions to recorded answers. These interviews
were recorded inside a large Light Stage system
with fifty-four high-definition video cameras. The multiview
data enabled the conversations to be projected threedimensionally
on an automultiscopic display.
The light stage system is designed for recording relightable
reflectance fields, where the subject is illuminated
from one lighting direction at a time, and these datasets can
be recombined through image-based relighting. If the
subject is recorded with a high speed video camera, a large
number of lighting conditions can be recorded during a normal
video frame duration allowing a dynamic video
to be lit with new lighting. This enables the subject to be realistically
composited into a new environment (for example,
the place that the subject is speaking about) such that their
lighting is consistent with that of the environment. In 2012,
the project performed a successful early experiment using a
Spherical Harmonic Lighting Basis as in for relighting
a Holocaust survivor interview. However, recording with
an array of high speed cameras proved to be too expensive
for the project, both in the cost of the hardware, and the
greatly increased storage cost of numerous high-speed uncompressed
video streams.
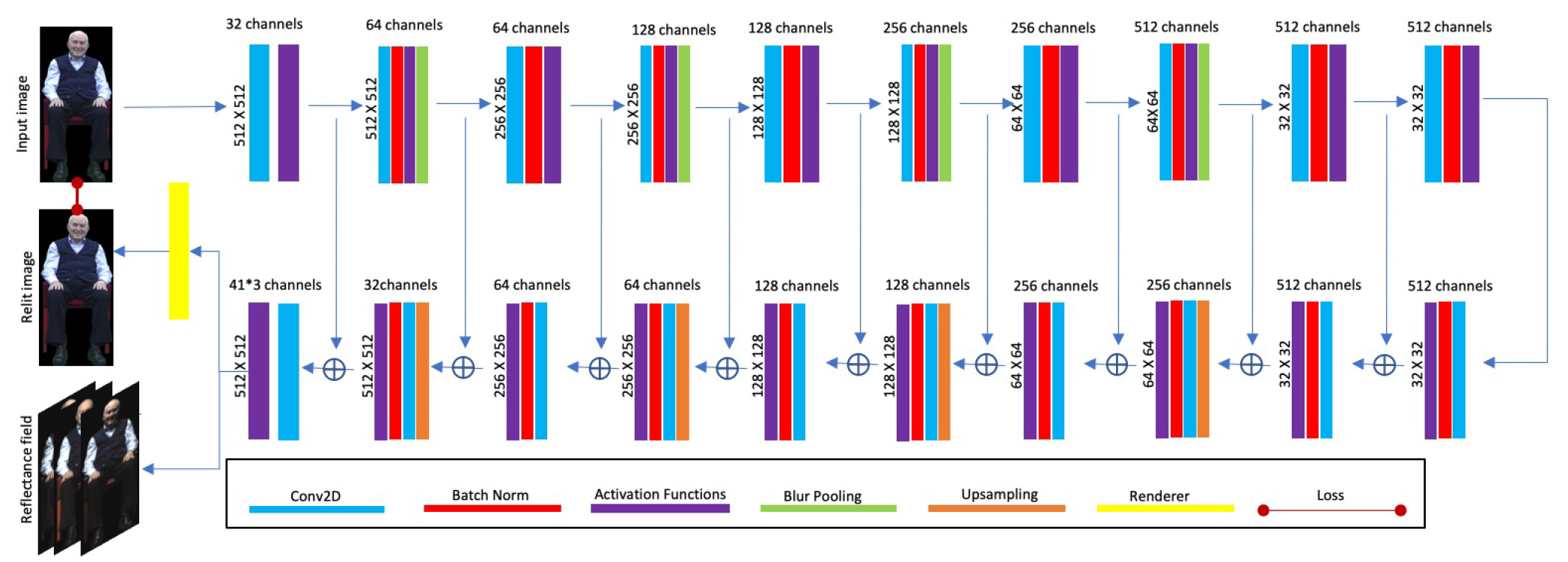
One of the most effective ways to perform realistic relighting
is to combine a dense set of basis lighting conditions
(a reflectance field) with according to a novel lighting
environment to simulate the appearance in the new lighting.
However, this approach is not ideal for a dynamic performance
since it requires either high-speed cameras, or requires
the actor to sit still for several seconds to capture
the set of OLAT images. [25] overcomes this limitation
by using neural networks to regress 4D reflectance fields
from just two images of a subject lit by gradient illumination.
They postulate that one can also use flat-lit images
to achieve similar results with less high-frequency detail.
Since the method casts relighting as a supervision regression
problem, it requires pairs of tracking images and their
corresponding OLAT images as ground truth for training.
In the New Dimensions in Testimony project, most of
the Holocaust survivors’ interview footage was captured
in front of a green screen so that the virtual backgrounds
can be added during post-production. However, this setup
poses difficulties for achieving consistent illumination between
the actors and the backgrounds in the final testimony
videos and does not provide the ground truth needed for supervision
training. In this paper, we use the limited OLAT
data to train a neural network to infer reflectance fields from
synthetically relit images. The synthetic relit images are
improved by matching them with the input interview images
through a differentiable renderer, enabling an end-toend
training scheme.
