
Establishing dense correspondence between two images is a fundamental computer vision problem, which is typically tackled by matching local feature descriptors. However, without global awareness, such local features are often insufficient for disambiguating similar regions. And computing the pairwise feature correlation across images is both computation-expensive and memory-intensive. To make the local features aware of the global context and improve their matching accuracy, we introduce DenseGAP, a new solution for efficient Dense correspondence learning with a Graph-structured neural network conditioned on Anchor Points. Specifically, we first propose a graph structure that utilizes anchor points to provide sparse but reliable prior on inter- and intra-image context and propagates them to all image points via directed edges. We also design a graph-structured network to broadcast multi-level contexts via light-weighted message-passing layers and generate high-resolution feature maps at low memory cost. Finally, based on the predicted feature maps, we introduce a coarse-to-fine framework for accurate correspondence prediction using cycle consistency. Our feature descriptors capture both local and global information, thus enabling a continuous feature field for querying arbitrary points at high resolution. Through comprehensive ablative experiments and evaluations on large-scale indoor and outdoor datasets, we demonstrate that our method advances the state-of-the-art of correspondence learning on most benchmarks.
The following images show the concept and architecture design of our model.
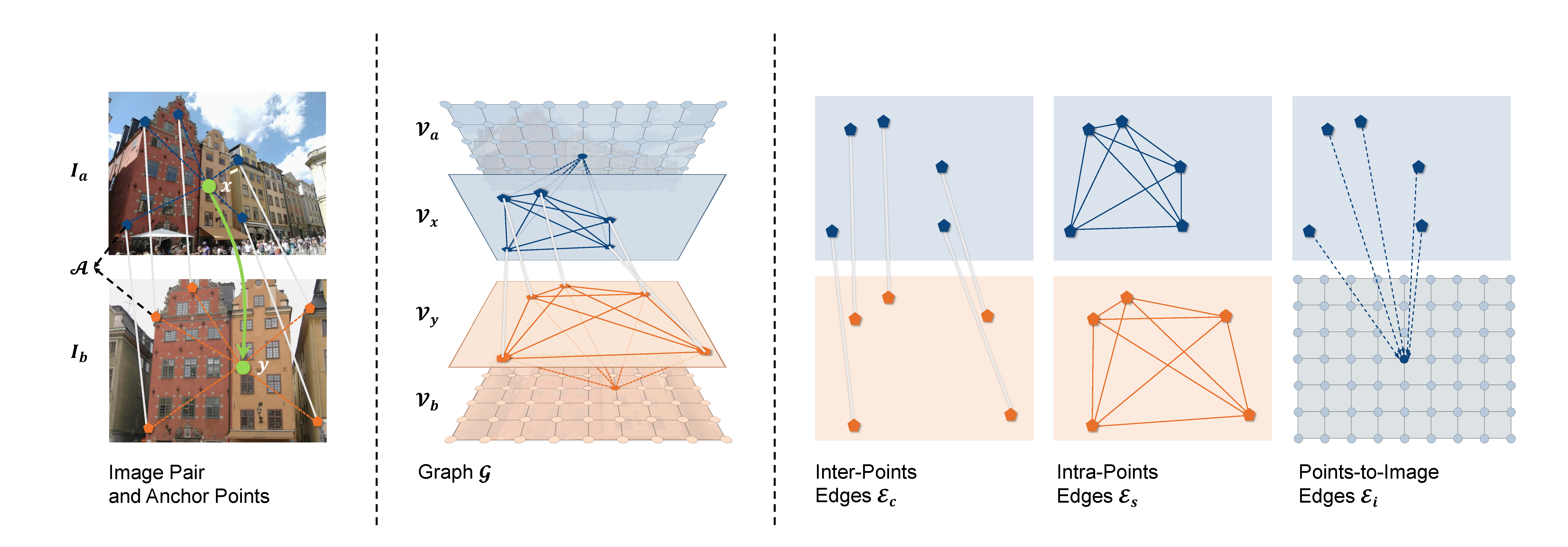
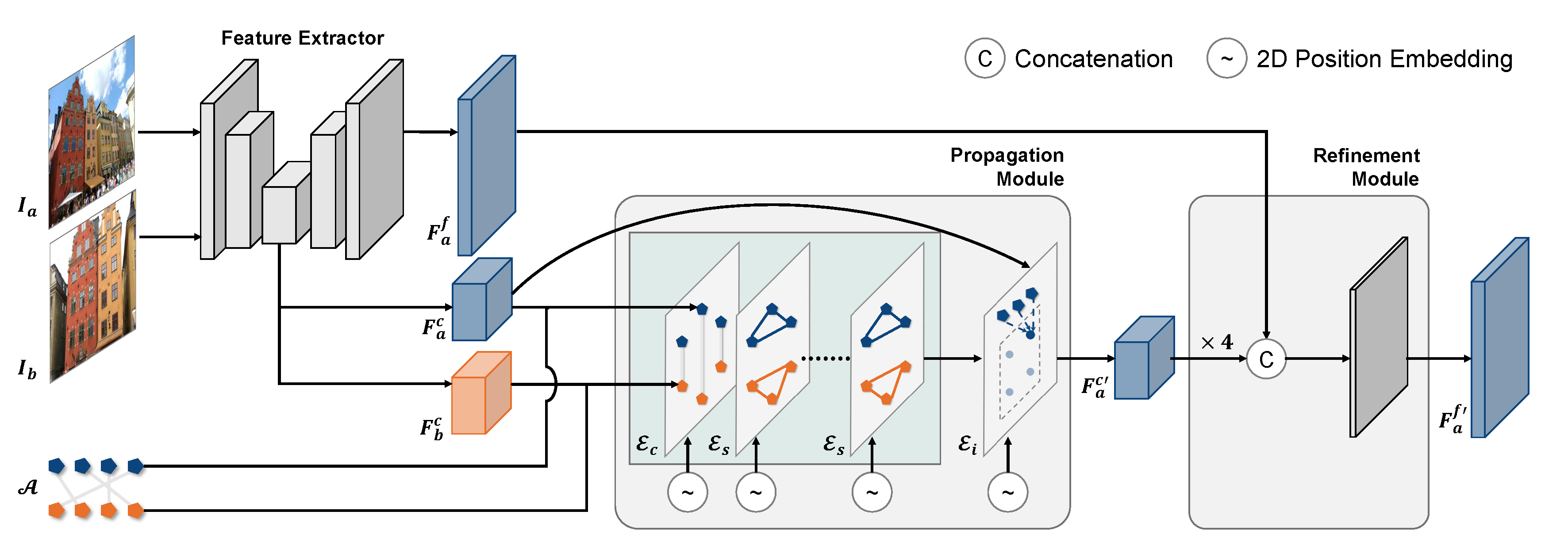
Overview of the framework. Given two images and anchor points, we first extract the coarse and fine feature maps of each image. Then we obtain the features of anchor points from the coarse feature maps as input to the Propagation Module. The output of the module is updated coarse feature maps, and is then fed with the fine feature maps to the Refinement Module.This module finally generates the updated fine feature maps.
Sparse matching results on MegaDepth, compared with DualRC-Net and SuperGlue.

The reference image (1st column) is warped to the query image (2nd column) based on the dense correspondences generated by the baseline method (3rd) and our model (4th). The confidence maps of our predictions (represented by cycle consistency) are also shown in the5thcolumn. The black pixels in the confidence map represent those with the cycle consistency larger than 10 pixels.
This research is sponsored by the Department of the Navy, Office of Naval Research under contract number N00014-21- S-SN03 and in part sponsored by the U.S. Army Research Laboratory (ARL) under contract number W911NF-14-D-0005. Army Research Office sponsored this research under Cooperative Agreement Number W911NF-20-2-0053. Statements and opinions expressed, and content included, do not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.