
This paper presents the first end-to-end network for exemplar-based video colorization. The main challenge is to achieve temporal consistency while remaining faithful to the reference style. To address this issue, we introduce a recurrent framework that unifies the semantic correspondence and color propagation steps. Both steps allow a provided reference image to guide the colorization of every frame, thus reduce accumulated propagation errors. Video frames are colorized in sequence based on the history of colorization, and its coherency is further enforced by the temporal consistency loss. All of these components, learnt end-toend, help produce realistic videos with good temporal stability. Experiments show our result is superior to the stateof-the-art methods both quantitatively and qualitatively.
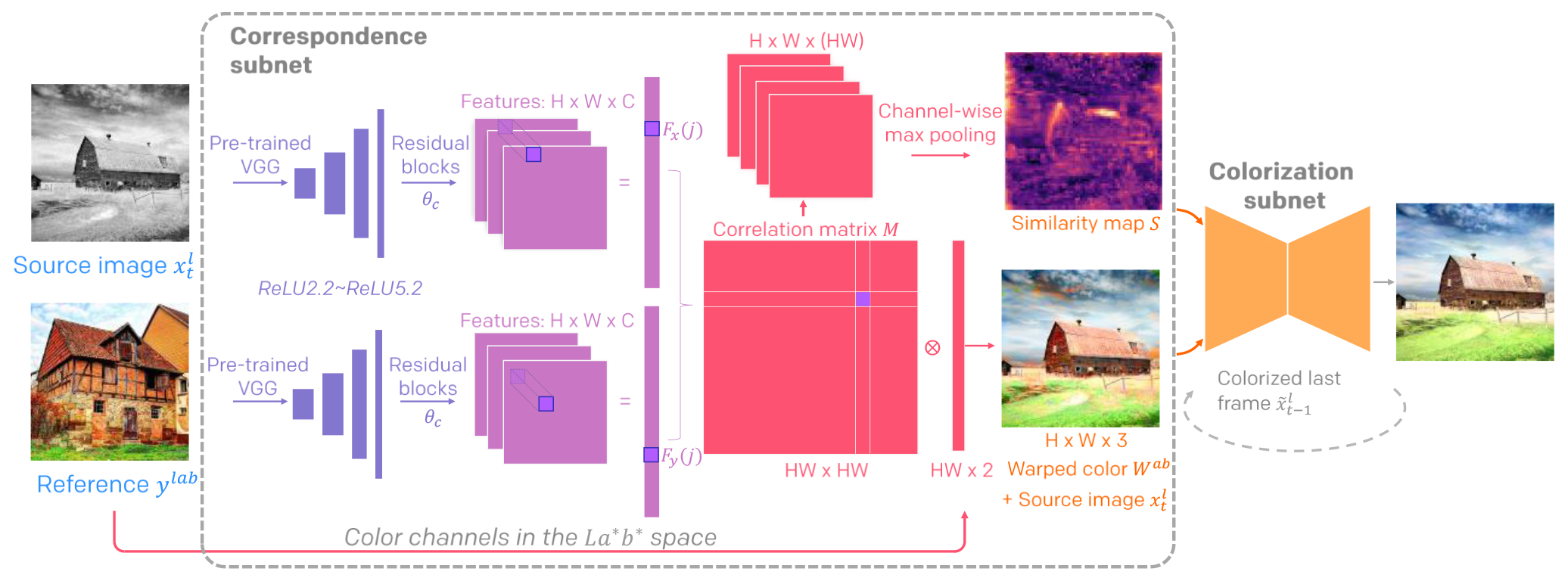
Network Structure. The correspondence network involves 4 residual blocks each with 2 conv layers. The colorization subnet adopts an auto-encoder structure with skipconnections to reuse the low-level features. There are 3 convolutional blocks in the contractive encoder and 3 convolutional blocks in the decoder which recovers the resolution; each convolutional block contains 2~3 conv layers. The tanh serves as the last layer to bound the chrominance output within the color space. The video discriminator consists of 7 conv layers where the first six layers halve the input resolution progressively. Also, we insert the self-attention block after the second conv layer to let the discriminator examine the global consistency. We use instance normalization since colorization should not be affected by the samples in the same batch. To further improve training stability we apply spectral normalization on both generator and discriminator as suggested in.
In this section, we first study the effectiveness of individual components in our method. Then, we compare our method with state-of-the-art approaches.
In this work, we propose the first exemplar-based video colorization. We unify the semantic correspondence and colorization into a single network, training it end-to-end. Our method produces temporal consistent video colorization with realistic effects. Readers could refer to our supplementary material for more quantitative results.